
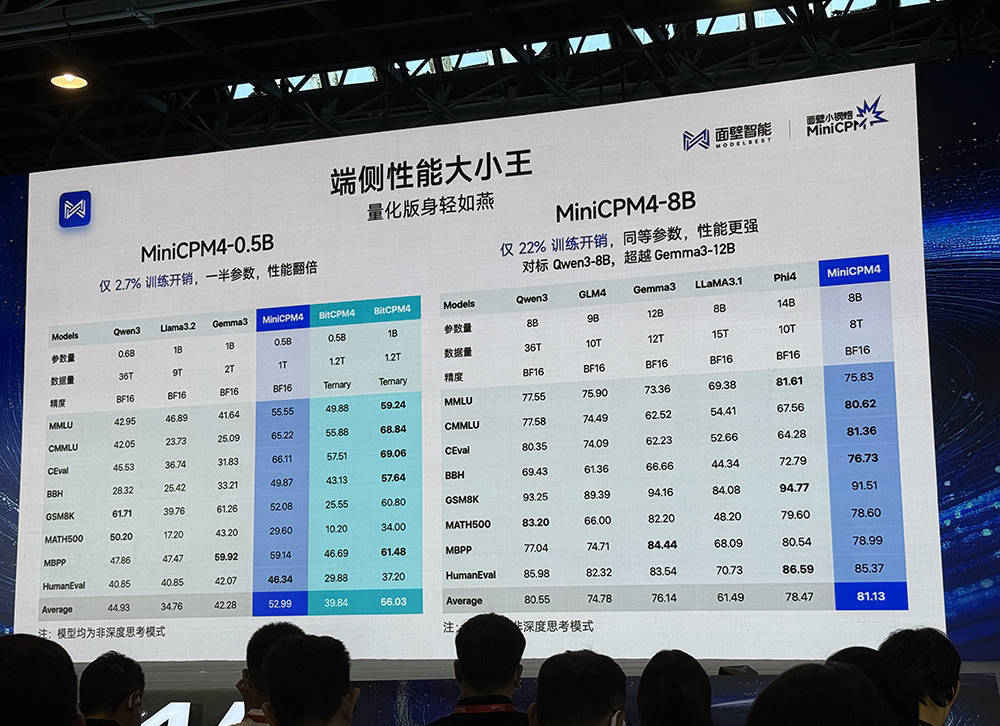
智东西智东西6月7日报道,在2025智源大会期间,北京大模型创企面壁智能发布开源模型MiniCPM4.0的两个新版本(0.5B、8B),代号「前进四」。
MiniCPM4-0.5B训练开销仅为Qwen3-0.6B的2.7%,以一半参数目实现翻倍性能,综合得分平均分为52.06分,远超同类模型。面壁科技还发布了一个0.5B的三级量化版本,平均得分是56分,是非常好的成绩。
MiniCPM4-8B训练开销仅22%,加了长下文稀疏化版本,做到同等参数、性能更强,综合得分对标Qwen3-8B、超越Gemma3-12B,在下列同类端侧模型排行榜中分数排名第一。
智东西智东西6月7日报道,在2025智源大会期间,北京大模型创企面壁智能发布开源模型MiniCPM4.0的两个新版本(0.5B、8B),代号「前进四」。
MiniCPM4-0.5B训练开销仅为Qwen3-0.6B的2.7%,以一半参数目实现翻倍性能,综合得分平均分为52.06分,远超同类模型。面壁科技还发布了一个0.5B的三级量化版本,平均得分是56分,是非常好的成绩。
MiniCPM4-8B训练开销仅22%,加了长下文稀疏化版本,做到同等参数、性能更强,综合得分对标Qwen3-8B、超越Gemma3-12B,在下列同类端侧模型排行榜中分数排名第一。
面壁智能CEO李大海总结说,MiniCPM4模型最大的特点就是快。
在端侧跑140K上下文,需要很大的端侧内存,属于极端场景。在JetsonOrinAGX(64G)或RTX4090(24G)硬件上运行128K长文本时,像Qwen3-8B这样没做过上下文稀疏化的模型,显存不够用,需要用CPU内存,offload导致速度急速下降;而MiniCPM4-8B做了快速稀疏化工作,可将占用的低长文本缓存降至1/4,在常规场景里至少可以取得3-5倍的速度优势。
面壁智能CEO李大海总结说,MiniCPM4模型最大的特点就是快。
在端侧跑140K上下文,需要很大的端侧内存,属于极端场景。在JetsonOrinAGX(64G)或RTX4090(24G)硬件上运行128K长文本时,像Qwen3-8B这样没做过上下文稀疏化的模型,显存不够用,需要用CPU内存,offload导致速度急速下降;而MiniCPM4-8B做了快速稀疏化工作,可将占用的低长文本缓存降至1/4,在常规场景里至少可以取得3-5倍的速度优势。
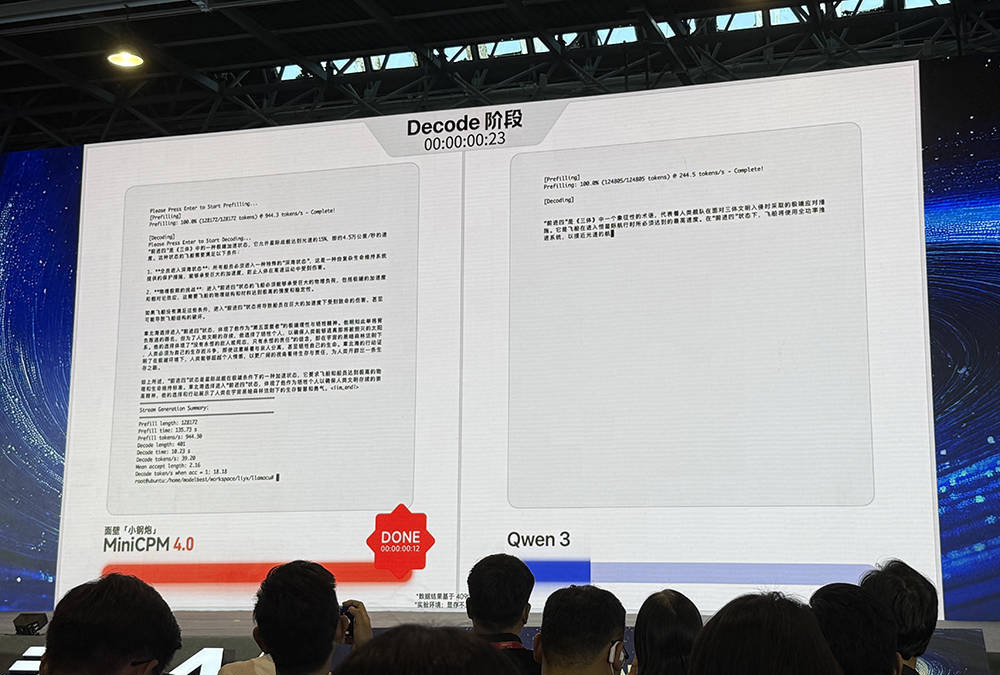
在显存受限的极限场景中,MiniCPM4的测试数据甚至可以快到220倍。
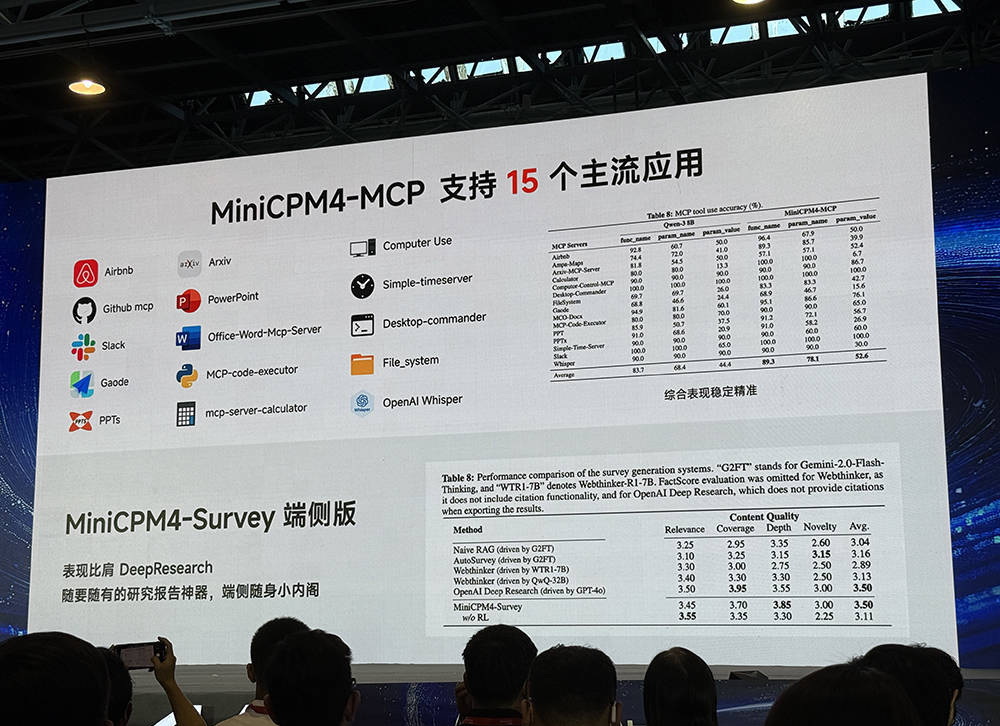
面壁智能的MiniCPM4-MCP模型,在端侧利用MCP协议,支持15个主流应用,取得了很高的综合评测表现得分。另一个MiniCPM4-Survey端侧版可在AIPC上构建DeepResearch(深度研究)服务,是一个离线可用的随身研究报告利器,有助于保护本地隐私数据。
在显存受限的极限场景中,MiniCPM4的测试数据甚至可以快到220倍。
面壁智能的MiniCPM4-MCP模型,在端侧利用MCP协议,支持15个主流应用,取得了很高的综合评测表现得分。另一个MiniCPM4-Survey端侧版可在AIPC上构建DeepResearch(深度研究)服务,是一个离线可用的随身研究报告利器,有助于保护本地隐私数据。
面壁智能与英特尔紧密合作,首次端侧解锁128K长上下文窗口,在英特尔平台上基于InfLLM2.0稀疏注意力结构已实现3.8倍加速的推理优化效果。同时,MiniCPM4已经可以在华为昇腾、联发科、高通等主流芯片上流畅运行,也支持vLLM、AutoGPT等推理框架,欧拉版正在积极适配中。
面壁智能与英特尔紧密合作,首次端侧解锁128K长上下文窗口,在英特尔平台上基于InfLLM2.0稀疏注意力结构已实现3.8倍加速的推理优化效果。同时,MiniCPM4已经可以在华为昇腾、联发科、高通等主流芯片上流畅运行,也支持vLLM、AutoGPT等推理框架,欧拉版正在积极适配中。

又快又好,是怎么做到的?
李大海分享了背后的技术细节——行业首个全开源系统级上下级稀疏化高效创新。
又快又好,是怎么做到的?
李大海分享了背后的技术细节——行业首个全开源系统级上下级稀疏化高效创新。

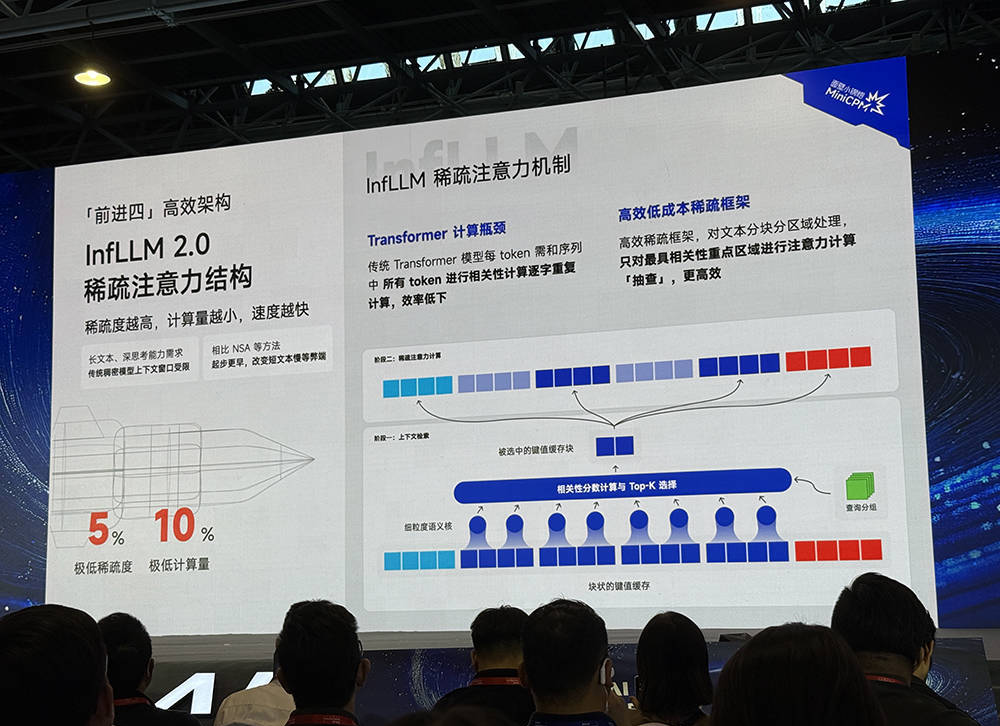
传统Transformer模型每token需和序列中所有token进行相关性计算逐字重复计算,效率低下。在稀疏注意力机制下,稀疏度越高,计算量越小,速度越快。
MiniCPM4采用了InfLLM2.0混合稀疏注意力结构。该架构采用类似于检索的思路,对文本分块分区域处理,只对最具相关性重点区域进行注意力计算“抽查”,更加高效。通过这种方式,面壁智能可将稀疏度降到5%,将计算量降到10%。
同时,面壁智能还立异地采用了高效的自动双频换挡技术,长文本用稀疏方案,短文本用稠密方案。
传统Transformer模型每token需和序列中所有token进行相关性计算逐字重复计算,效率低下。在稀疏注意力机制下,稀疏度越高,计算量越小,速度越快。
MiniCPM4采用了InfLLM2.0混合稀疏注意力结构。该架构采用类似于检索的思路,对文本分块分区域处理,只对最具相关性重点区域进行注意力计算“抽查”,更加高效。通过这种方式,面壁智能可将稀疏度降到5%,将计算量降到10%。
同时,面壁智能还立异地采用了高效的自动双频换挡技术,长文本用稀疏方案,短文本用稠密方案。
端侧生态丰富,兼容是一件成本较高的事。面壁智能希望尽可能简化端侧模型部署的复杂度,自研了“三级火箭”推理框架。
端侧生态丰富,兼容是一件成本较高的事。面壁智能希望尽可能简化端侧模型部署的复杂度,自研了“三级火箭”推理框架。

(1)自研端侧高性能推理框架CPM.cu:实现稀疏、投机和量化的高效结合,通过FR-Spec轻量化投机采样,相比原始模型提速2倍,让小模型给大模型当实习生,给小模型减负加速,速度提升超5倍。
(2)极致低位宽量化BitCPM:端侧低内存容量部署友好,4bit量化达到业界SOTA等级,3倍量化,可瘦身90%。
(3)自研跨平台部署框架Arkinfer:面向多平台端侧芯片极致优化,跨平台高效投机采样和限制解码,支持端侧多平台ModelZoo的丝滑使用,速度提升2倍。
在高效训练方面,面壁智能也做了很多探索。
(1)模型风洞ModelWindTunnelv2:用小模型给大模型探路,通过高效训练小模型,寻求大模型训练最佳配置,将学习率、批大小等移至大模型训练,完成最优配置搜索。
(2)Chunk-wiseRollout负载均衡强化学习:强化学习训练中,单一数据过长时,将在GPU上产生大量空泡,导致负载不均,因此将长数据分段采样,使其在下一阶段继续生成,以此实现GPU资源的高效分配。
(3)工程优化:采用FP8训练,以低精度加速模型计算,提升训练效率;采用MTP监督信号,提供更稠密的监督信号,提升模型数据利用率。
MiniCPM4模型还有一个重要优势:只用了非常少的高质量训练语料。
好数据才能跑出好性能。8T的面壁高质量数据,与36T竞品数据的模型训练效果相当。
(1)Ultra-FineWeb:高效数据严格筛选机制,可构建万亿高质量数据集,通过“半成品加工法”高效验证,先训一个’半熟”模型,再用新数据快速微调,能够将成本降低90%;用fastText工具进行大语言模型质检,处理15万亿数据只需1000小时CPU。
(2)UltraChat-v2:高能力密度数据合成,可构建大规模知识密集型、推理密集型、指令遵循型、长文本处理型、工具调用型等多样化的有监督微调数据。
总体来看,MiniCPM4以更少参数目实现出色性能的背后,是面壁智能从架构层、系统层、推理层到数据层的层层优化。而用更少的数据和算力做出同等性能的模型,意味着降低成本,能将时间和资源用于做更多、更有价值的事。
作为国内端侧模型代表,面壁智能旗下模型矩阵已覆盖基座模型MiniCPM、旗舰多模态模型MiniCPM-V、旗舰全模态模型MiniCPM-o,全球下载量超千万。
(1)自研端侧高性能推理框架CPM.cu:实现稀疏、投机和量化的高效结合,通过FR-Spec轻量化投机采样,相比原始模型提速2倍,让小模型给大模型当实习生,给小模型减负加速,速度提升超5倍。
(2)极致低位宽量化BitCPM:端侧低内存容量部署友好,4bit量化达到业界SOTA等级,3倍量化,可瘦身90%。
(3)自研跨平台部署框架Arkinfer:面向多平台端侧芯片极致优化,跨平台高效投机采样和限制解码,支持端侧多平台ModelZoo的丝滑使用,速度提升2倍。
在高效训练方面,面壁智能也做了很多探索。
(1)模型风洞ModelWindTunnelv2:用小模型给大模型探路,通过高效训练小模型,寻求大模型训练最佳配置,将学习率、批大小等移至大模型训练,完成最优配置搜索。
(2)Chunk-wiseRollout负载均衡强化学习:强化学习训练中,单一数据过长时,将在GPU上产生大量空泡,导致负载不均,因此将长数据分段采样,使其在下一阶段继续生成,以此实现GPU资源的高效分配。
(3)工程优化:采用FP8训练,以低精度加速模型计算,提升训练效率;采用MTP监督信号,提供更稠密的监督信号,提升模型数据利用率。
MiniCPM4模型还有一个重要优势:只用了非常少的高质量训练语料。
好数据才能跑出好性能。8T的面壁高质量数据,与36T竞品数据的模型训练效果相当。
(1)Ultra-FineWeb:高效数据严格筛选机制,可构建万亿高质量数据集,通过“半成品加工法”高效验证,先训一个’半熟”模型,再用新数据快速微调,能够将成本降低90%;用fastText工具进行大语言模型质检,处理15万亿数据只需1000小时CPU。
(2)UltraChat-v2:高能力密度数据合成,可构建大规模知识密集型、推理密集型、指令遵循型、长文本处理型、工具调用型等多样化的有监督微调数据。
总体来看,MiniCPM4以更少参数目实现出色性能的背后,是面壁智能从架构层、系统层、推理层到数据层的层层优化。而用更少的数据和算力做出同等性能的模型,意味着降低成本,能将时间和资源用于做更多、更有价值的事。
作为国内端侧模型代表,面壁智能旗下模型矩阵已覆盖基座模型MiniCPM、旗舰多模态模型MiniCPM-V、旗舰全模态模型MiniCPM-o,全球下载量超千万。
来源:头条娱乐